Tracking Dexterous Hands: System Trade-offs for Scaling Robot Learning
By Shumo Chu and GI Labs Team
Teaching a robot to manipulate objects with dexterous hands requires capturing how humans do it first — the precise finger poses, wrist trajectories, and contact forces that make grasping and in-hand manipulation work. Whether training via imitation learning or bootstrapping reinforcement learning from demonstrations, the quality of this captured motion data directly determines what behaviors a robot can learn.
But capturing dexterous hand motion is hard. Optical mocap gives sub-millimeter accuracy but requires a multi-camera IR cage costing $30K–300K+ — you can't take it to a kitchen. IMU gloves are portable but accumulate yaw drift without an absolute heading reference. Electromagnetic sensors work through occlusion but are sensitive to nearby metals that distort the tracking field. Each technology has its own limitations, and building a practical system for dexterous manipulation means understanding which trade-offs matter for your setting.
This post walks through the major tracking technologies, their trade-offs, and how recent systems combine them — drawn from our full report.[1]
The Three Categories of Tracking
Every motion capture system outputs 6-DoF pose (position + orientation) or joint angles — and dexterous manipulation typically needs both. We group technologies into three categories: external global tracking systems that use environment-mounted infrastructure to provide absolute pose, onboard and relative sensing that uses sensors carried on the hand itself, and internal joint-state sensing that directly measures finger articulation. The table below summarizes the key trade-offs — color-coded by category.
| System | Accuracy | Drift | LoS | Infra. | Env. Sensitivity |
|---|---|---|---|---|---|
| Passive Optical | <1 mm | None | Yes | High | Lighting, occlusion |
| Active Optical | <1 mm | None | Yes | High | Lighting, occlusion |
| Lighthouse | 1–10 mm | None | Yes | Med. | Reflections, geometry |
| IMU | 0.1–2° (ori.) | Accumulates | No | None | Magnetic disturbances |
| Electromagnetic | ~0.5 mm | None | No | None | Metals (critical) |
| VI-SLAM | cm-scale | Bounded | No | None | Texture, dynamics |
| Joint Encoders | 0.1–0.4° | None | No | None | Minimal |
The pattern is clear: modalities offering high absolute accuracy require external infrastructure, while portable approaches sacrifice global consistency.
External Global Tracking


Passive and active optical systems (Vicon, OptiTrack, PhaseSpace) use IR cameras to triangulate markers — sub-millimeter accuracy and no drift, but line-of-sight requirements and multi-camera cage infrastructure ($30K–300K+) confine them to instrumented labs. Active systems replace retroreflective markers with coded LEDs, eliminating marker-swap errors at up to 960 Hz.[2] Both are the gold standard for ground-truth benchmarking but impractical for in-the-wild data collection.
Lighthouse tracking (SteamVR) uses timed IR sweeps from base stations rather than cameras. With 4 base stations, static accuracy is sub-millimeter, but dynamic motion introduces 10–11 mm errors.[3] At $300–1K for a base station setup, lighthouse tracking has become the go-to for teleoperation and robotic data collection in lab settings.
Onboard Sensing: IMUs, EM, and SLAM


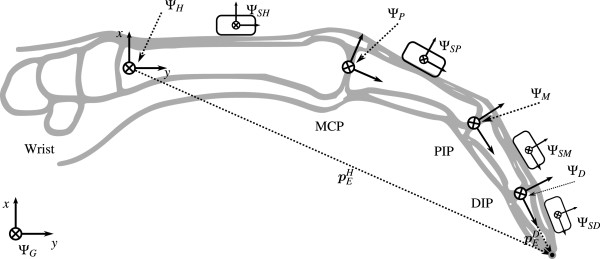
IMU-based gloves distribute MEMS IMUs across the hand — one per phalanx segment in full designs (15–18 per hand), or 6–7 in budget versions that infer intermediate joints via biomechanical coupling constraints. Each finger is modeled as a serial kinematic chain: the MCP joint provides 2 DoF (flexion/extension + abduction/adduction), while PIP and DIP each provide 1 DoF, yielding ~20 DoF for the full hand.[4] Joint angles are extracted from the relative orientation between adjacent IMUs — this differential measurement cancels common-mode errors, so joint angle estimates remain accurate even when absolute orientation drifts.[5]
The key trade-off is between 6-axis and 9-axis IMUs. A 9-axis IMU adds a magnetometer that provides an absolute heading (yaw) reference via the Earth's magnetic field. But Earth's field is weak (~25–65 µT), making magnetometers vulnerable to hard-iron and soft-iron interference from nearby metals and electronics. A 6-axis configuration avoids this entirely: yaw becomes relative and drifts over time, but the estimate is immune to magnetic interference. This matters especially when IMU gloves are used alongside electromagnetic tracking, where the EM field generator would overwhelm the magnetometer. Adaptive approaches offer a middle ground — trusting the magnetometer only when the ambient field is stable and falling back to 6-axis operation during disturbances.
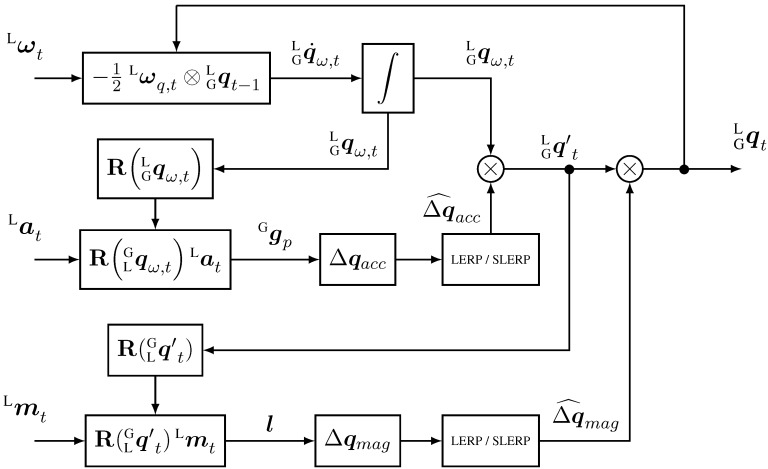
In practice, IMU gloves achieve dynamic orientation accuracy of ±0.5° for pitch/roll and ±1–2° for yaw at up to 120 Hz (e.g., VRTRIX PRO).[6] Orientation is estimated reliably, but absolute position must be inferred through kinematic constraints or external references — it cannot be measured by IMUs alone. Hybrid architectures like the Rokoko Smartgloves combine IMU sensors with a local electromagnetic field coil, using the EMF signal for drift-free absolute position when within range and falling back to IMU-only tracking otherwise.
Electromagnetic tracking estimates finger pose by exploiting alternating magnetic fields.[7] A field generator (typically wrist-mounted for hand tracking) emits a quasi-static electromagnetic field, and small receiver coils on each finger segment measure the induced response. By modeling how the field varies spatially, these signals are inverted to recover 6-DoF position and orientation of each sensor relative to the generator's frame — making EM an onboard, relative sensing modality like IMU gloves, not an external system.
Three families of EM systems see use in hand tracking. Polhemus systems achieve sub-millimeter accuracy at 100–120 Hz in controlled environments. NDI Aurora, a medical-grade system, reports ~0.5 mm RMS positional accuracy with sub-degree orientation within its operating volume.[8] Manus Quantum Metagloves integrate the field generator into a wrist-mounted package, providing millimeter-level finger tracking that remains robust through visual occlusion.
The key advantage is occlusion immunity: EM tracking works through physical contact and visual obstructions that defeat optical methods, with no drift. The limitation is environmental — conductive metals induce eddy currents that distort the field, and ferromagnetic materials cause nonlinear distortions. Most tabletop and lab settings have sufficiently little metal for reliable operation, but industrial environments with metal fixtures remain problematic. Because the wrist-mounted generator moves with the hand, workspace size is not a constraint for finger tracking — but recovering absolute global hand pose still requires an external reference.
SLAM (Simultaneous Localization and Mapping) estimates motion by jointly inferring the sensor's pose and a map of the environment from onboard cameras, LiDAR, or depth sensors.[9] Modern SLAM systems decompose into a front-end that extracts features and establishes correspondences across time, and a back-end that optimizes these constraints — typically as a factor graph — to obtain locally consistent trajectory and map estimates. Loop closures (recognizing previously visited locations) introduce additional constraints that reduce accumulated drift.
Multiple algorithmic families exist. Classical visual SLAM (e.g., ORB-SLAM[10]) uses sparse feature detection with epipolar geometry and bundle adjustment. Direct methods (e.g., DSO[11]) minimize photometric error over image intensities, improving performance in low-texture scenarios at the cost of illumination sensitivity. LiDAR-based systems use geometric registration (ICP, scan matching) on dense point clouds. Learning-based methods like DROID-SLAM[12] use neural feature extraction, improving robustness to illumination and texture-poor scenes but with reduced geometric guarantees.
SLAM scales naturally to large environments without external infrastructure, making it the go-to for portable tracking. But error accumulates with distance and time — loop closure bounds but cannot eliminate drift, and performance depends strongly on environmental structure (visual SLAM degrades in low-texture, repetitive, or dynamic scenes). SLAM estimates are unsuitable as ground truth but serve as the primary localization backbone during deployment.
Consumer XR headsets (Meta Quest 3, Apple Vision Pro) have become the most widely deployed VI-SLAM devices in robotics teleoperation, achieving sub-centimeter headset RPE. However, these devices differ significantly in architecture beyond headset SLAM — Quest 3 combines VI-SLAM with active optical controller tracking and markerless hand tracking at very different accuracy tiers, while Vision Pro relies on markerless hand tracking alone. These differences have practical consequences for robotics data collection, discussed in Combining Modalities below.
Internal Joint-State Sensing
Magnetic encoders measure joint angles directly via contactless Hall-effect sensing. A small permanent magnet attached to a rotating joint is read by Hall-effect or magnetoresistive sensors to infer angle — compact, contactless, and robust to dust, vibration, and wear, making them well suited for densely packed joints. The AS5600, widely used in robotic hands, provides 12-bit resolution (~0.087° per step), with practical precision of 0.1–0.4° depending on magnet alignment and calibration. Measurements are absolute, drift-free, and immune to the environmental factors that affect other modalities.
The key limitation: encoders observe joint angles, not spatial pose. End-effector position and orientation can only be recovered through forward kinematics, which requires accurate kinematic models and a known base pose. Uncertainty in link lengths, joint offsets, or base motion propagates through the kinematic chain into task-space error — and joint encoders alone cannot recover absolute global pose. For tasks requiring spatial awareness, they must be combined with external or onboard sensing.
Despite this, in dexterous hands with dozens of closely spaced joints, encoders remain one of the most practical ways to observe fine-grained finger articulation and contact configurations. While external or onboard sensing estimates hand motion as a whole, precise manipulation control benefits significantly from joint-level measurements.
Combining Modalities
Dexterous manipulation demands simultaneous knowledge of global pose, finger articulation, and often contact state — no single sensor addresses all these requirements. This has driven researchers toward multimodal systems that combine complementary sensors. But physical constraints impose hard limits on which modalities can coexist:
- EM + IMU conflict: The EM field generator — orders of magnitude stronger than Earth's field at close range — overwhelms IMU magnetometers, rendering yaw estimates unreliable. Systems must drop magnetometer fusion or spatially isolate subsystems.
- EM + metal: Conductive metals induce eddy currents that distort the EM field; ferromagnetic materials cause nonlinear distortions. This limits EM tracking in industrial settings with metal fixtures and workpieces.
- Optical + occlusion/wearables: Self-occlusion during grasping is the dominant failure mode for vision-based finger tracking — fingers disappear behind objects precisely when accurate pose matters most. Wearing gloves or exoskeletons further degrades markerless hand detection; DexUMI addresses this by inpainting the gloved hand in RGB observations.
Fusion Architectures
Given these constraints, how do systems actually combine sensors? We identify five architectural patterns:
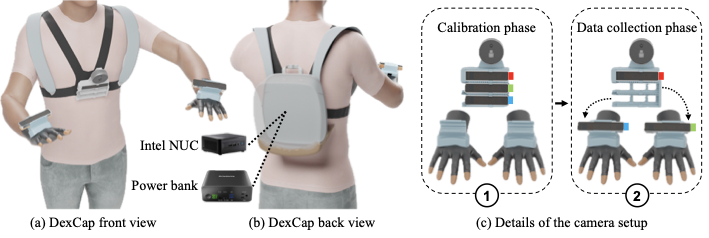
Hierarchical fusion assigns different sensors to disjoint degrees of freedom. DexCap[13] pairs SLAM cameras for wrist pose with EMF gloves for fingers — the two subsystems measure disjoint quantities and compose via forward kinematics. OSMO similarly separates vision-based hand tracking from tactile contact sensing.
Redundant fusion with filtering combines overlapping measurements via EKF variants. The key insight: sensor weaknesses are often uncorrelated — optical systems fail during occlusion while IMUs drift — so combining both inherits strengths. VIST[14] fuses glove IMUs with stereo cameras in an EKF, maintaining hand tracking through occlusion, EM interference, and physical contact. HandCept fuses wrist-mounted RGB-D with finger IMUs for proprioceptive hand pose estimation.
Reference anchoring uses one sensor as a drift-free anchor for others. ARCap[15] uses a Meta Quest 3 headset as the global frame with mocap gloves for fingers — test-time AR alignment replaces offline calibration, letting users match a virtual robot to the physical one in seconds. EgoAllo estimates full body and hand pose from VI-SLAM head tracking via a conditional diffusion model. HaWoR reconstructs world-space hand trajectories from egocentric video using an adaptive SLAM pipeline.
Learning-based fusion trains neural networks to weight multimodal inputs. Cross-modal transformers can learn attention-based reliability weighting between visual and tactile streams, adapting to context without explicit sensor models — unlike model-based EKF approaches that require specifying noise covariances a priori.
Embodiment-isomorphic design sidesteps fusion entirely by mechanically matching the human hand to the robot. DEXOP and MILE use exoskeletons whose joint structure mirrors the target robot hand, so finger motion maps directly to robot commands without retargeting. DexUMI attaches robot fingers directly to the human hand, using the physical coupling as an implicit sensor for finger pose.
Case Study: Consumer XR as Tracking Backbone
Consumer XR headsets illustrate how multiple sensing modalities combine in a single consumer product — and why "XR tracking" is not a single accuracy number.
Meta Quest 3 is a hybrid system combining three subsystems at different accuracy tiers: (1) VI-SLAM headset localization via four tracking cameras and one IMU (~0.77 cm RPE)[16], (2) active IR LED constellation tracking for controllers — the headset cameras observe known LED patterns on the Touch Plus controllers and solve pose via PnP, the same principle as PhaseSpace active optical mocap but inside-out — achieving low-millimeter accuracy relative to the headset[17], and (3) markerless hand tracking via computer vision (~1.73 cm average error).[18] Critically, the low-millimeter controller figure describes controller-to-headset relative pose, not world-frame accuracy — global controller accuracy is still bounded by the headset's VI-SLAM.
Apple Vision Pro takes a fundamentally different approach: superior VI-SLAM headset tracking (~0.52 cm RPE via six cameras, four IMUs, a LiDAR scanner, and a dedicated R1 co-processor) but no controllers at all. Hand input relies entirely on markerless tracking and eye gaze.
This architectural difference has direct consequences for robotics. For teleoperation, controller-to-headset relative precision drives control quality during an episode — Quest controllers offer low-mm relative precision while Vision Pro's markerless hands offer ~sub-cm. But both share centimeter-scale global accuracy bounded by headset SLAM. For comparison, SteamVR Lighthouse achieves sub-millimeter static accuracy in a fixed world frame — true global precision, but requiring dedicated base station infrastructure.
Systems in Practice
The table below summarizes representative multimodal systems:
| System | Global Tracking | Hand/Finger | Tactile/Haptic | Fusion | Cost |
|---|---|---|---|---|---|
| DexCap | SLAM (T265) | EMF gloves | — | Hierarchical | $3–5k |
| ARCap | Quest 3 | Mocap gloves | Haptic warnings | Ref. anchor | $1–2k |
| Open Teach | SteamVR | SteamVR | — | Ref. anchor | $1–2k |
| Open-TeleVision | Vision Pro | Vision Pro hands | — | Ref. anchor | $4–5k |
| Bunny-VisionPro | Vision Pro | Vision Pro hands | Haptic finger cots | Ref. anchor | $4–5k |
| AnyTeleop | RGB-D | Vision (hand det.) | — | Vision-only | $1–2k |
| DEXOP | Ext. tracking | Exoskeleton | — | Isomorphic | — |
| MILE | — | Exo. + tactile | Fingertip tactile | Isomorphic | — |
| HATO | — | Allegro teleop | Fingertip tactile | Hierarchical | — |
| DOGlove | — | Glove (hall effect) | Force feedback | Hierarchical | $50 |
| OSMO | Vision-based | — | 12×3-axis tactile | Hierarchical | — |
XR-anchored systems. ARCap uses Quest 3's controllers as tracked endpoints — tapping the low-mm controller-to-headset precision (see case study above) for fine-grained teleoperation input, with mocap gloves for fingers. Open-TeleVision and Bunny-VisionPro use Apple Vision Pro as a single device for both global tracking and hand input, relying on its markerless hand tracking (~sub-cm relative precision) since Vision Pro has no controllers. Bunny-VisionPro adds haptic finger cots for force feedback.
Standalone SLAM and lighthouse systems. DexCap pairs dedicated RealSense T265 cameras (VI-SLAM at 60 Hz) with EMF gloves for finger tracking, using a quick-release buckle for camera transfer between human and robot. Open Teach uses SteamVR lighthouse tracking (external IR base stations) rather than visual-inertial sensing, providing a modular framework for bimanual teleoperation.
Vision-only and exoskeleton systems. AnyTeleop uses only RGB-D cameras for both arm and hand tracking — no wearable hardware, but vulnerable to occlusion. DEXOP and MILE use exoskeletons mirroring the target robot hand, with MILE additionally integrating fingertip visuotactile sensors (GelSight Mini). DexUMI attaches robot fingers directly to the human hand, inpainting the operator's gloved hand in RGB observations to preserve visual policy learning.
Tactile-augmented systems. OSMO augments vision-based tracking with 12 three-axis magnetic tactile sensors (fingertips and palm) — on a contact-rich wiping task, tactile-equipped policies hit 72% success vs. ~30% vision-only.[19] HATO enables bimanual visuotactile teleoperation with Allegro hands and fingertip tactile sensors. DOGlove provides an open-source haptic glove for just $50, using hall-effect sensors for finger pose and electromagnetic actuators for force feedback.
Common challenges. Spatial calibration remains universal: each system must establish transforms between sensor frames and between human anatomy and robot kinematics — DexCap's quick-release mount and ARCap's AR alignment represent different trade-offs between precision and usability. Temporal synchronization across sensors at different rates (60 Hz SLAM, 90 Hz XR tracking, 1 kHz tactile) requires careful timestamp alignment. Embodiment retargeting — mapping human hand motion to kinematically dissimilar robot hands — is dominated by fingertip inverse kinematics, though recent work shows that preserving inter-finger distances captures grasp intent more faithfully than position alone.
Key Takeaways
Every modality trades off accuracy, drift, portability, and environmental robustness — which is why practical systems combine multiple sensors. From our analysis, four trends stand out:
-
Consumer XR has made portable global pose accessible — but architecture matters. Quest 3 and Vision Pro both provide centimeter-scale global pose via VI-SLAM, but Quest's active optical controller tracking adds low-mm relative precision for teleoperation while Vision Pro relies on markerless hands (~sub-cm). Choosing which subsystem to tap determines your accuracy tier.
-
Tactile augmentation is proving consequential. OSMO's 72% vs. 30% success gap on a contact-rich wiping task illustrates that for manipulation involving sustained contact, tactile state is not merely supplementary — it can be a primary signal. How broadly this generalizes across task types remains an open question.
-
Embodiment-isomorphic designs are growing. DEXOP, MILE, and DexUMI sidestep fusion and retargeting entirely through mechanical matching. This trades operator ergonomics for engineering simplicity.
As robotic learning scales beyond single-task demonstrations toward large, diverse datasets, the sensing systems that capture this data become a quiet but consequential bottleneck. What a policy can learn is bounded by what its training data can observe — missing contact forces, drifting wrist pose, or coarse finger tracking all propagate into the learned behavior. We hope this survey provides practitioners with the technical grounding to navigate these trade-offs and design capture systems matched to their learning and deployment requirements. The full survey with detailed technical analysis is available here.
Acknowledgements
We thank Yu Xiang from UT Dallas for insightful discussions on IMU sensing and sensor fusion, and Jessica Yin from NVIDIA for discussions on tactile sensing.